Last Updated: May 20, 2026

What Is MiniMax M2.7?
MiniMax M2.7 is a mixture-of-experts language model with 229 billion total parameters and 10 billion active per token. It has 256 expert modules, but only 8 are used for any single word it generates. This architecture gives it the knowledge of a massive model while keeping the computational cost manageable.
We deployed it on a single NVIDIA DGX Spark, a desktop AI computer with 128GB of shared memory. The goal was to replace our previous reasoning model (Step 3.5 Flash at 20.6 tok/s) with something faster and more capable.
After 12 phases of optimisation over a full day of work, we achieved 26.4 tok/s with 131,000 tokens of context. That is a 28 per cent speed improvement over Step 3.5 Flash, with a larger model and more context.
This article walks through exactly what we did, what worked, what did not, and what we learned along the way.

Phase 1: The Baseline (23.4 tok/s)
We downloaded the IQ4_XS quantised version of M2.7 from Hugging Face (unsloth/MiniMax-M2.7-GGUF, four shards totalling 108GB) and launched it with llama.cpp using standard settings.
The baseline result was 23.4 tok/s at 65K context with q8_0 KV cache. Cold start took about 8 minutes. This was already faster than Step 3.5 Flash (20.6 tok/s), which was encouraging.
But we knew from our previous experience with Qwen 3.6 that significant gains were possible through optimisation. The question was how much.
Phase 2: Verifying Flash Attention
Flash attention is an optimisation technique that reduces memory usage and speeds up the attention computation in transformer models. We checked the verbose logs to confirm it was actually enabled.
It was on, but we noticed that FA_ALL_QUANTS was off. This flag controls whether flash attention works with all quantisation types, including the IQ4_XS format our model uses. If it was falling back to a slower path, that could explain some lost performance.
Phase 3: Rebuilding llama.cpp with FA_ALL_QUANTS
We rebuilt llama.cpp from source with the FA_ALL_QUANTS flag enabled. This required specifying the correct CUDA architecture for the DGX Spark's GB10 chip (architecture 121).
The rebuild confirmed FA_ALL_QUANTS was on. But the benchmark showed no change: still 23.4 tok/s. Flash attention was already working correctly for our quantisation type. The flag was a no-op for this particular model and hardware combination.
Lesson learned: sometimes the obvious optimisation does nothing. Verify with actual benchmarks, not assumptions.
Phase 4: Extending Context to 131K
The baseline was running at 65K context. We wanted to push this higher because longer context means the model can work with larger documents and longer conversations.
At 98K context with q8_0 KV cache, we hit 116GB of memory usage with only 8GB free. That was too tight for safe operation.
The solution was switching the KV cache from q8_0 to q4_0. This halves the memory used for the key-value cache (the memory that stores the conversation history). The quality loss from q4_0 is minimal for generation tasks.
With q4_0 KV, 131K context used 112GB with 15GB free. Stable, safe, and giving us double the context window. This eliminated Step 3.5 Flash's context advantage.
Phase 5: Tool Call Validation
Before investing more time in speed optimisation, we needed to confirm the model could actually do its job. We tested five tool call scenarios: weather lookup, file reading, shell execution, multi-step chains, and nested arguments.
All five passed. M2.7 handles tool calls reliably with the standard chat template.
Phase 6: Batch Tuning (First Attempt)
We tested adjusting batch sizes with -b 2048 -ub 512. No significant change. For single-request throughput, batch size does not matter much. This was another dead end, but a quick one.
Phase 7: The MTP Investigation (All Paths Dead)
Multi-token prediction (MTP) is the single biggest potential speedup for inference. Instead of generating one token at a time, the model predicts multiple tokens simultaneously. Our Qwen 3.6 model uses MTP to hit 120 tok/s.
For M2.7, we investigated every possible path to enable MTP. Every single one was blocked.
Native MTP in GGUF: The conversion tool only supports Qwen and Gemma architectures, not minimax-m2.
External draft model: MTP requires a smaller "draft" model that shares the same vocabulary. M2.7 has a unique 200,064-token vocabulary. No other model family shares it. We checked Qwen, EAGLE3, and others. All incompatible.
ik_llama.cpp fork: Only supports MTP for Gemma4.
DFlash: Only tested with Qwen targets.
Custom MTP head: Would require training a 200M parameter head from scratch. A research project, not an overnight task.

This was the most frustrating phase. MTP could theoretically push M2.7 to 40-50 tok/s, but the unique vocabulary makes it impossible without custom model training.
Phase 8: Thread and Batch Tuning (The Winner!)
After the MTP disappointment, we went back to basics. This turned out to be where the real gains were hiding.
The key changes:
-t 16 -tb 16: Explicitly set 16 threads for inference and 16 for batch processing, instead of letting the system auto-detect--no-mmap: Load the entire 108GB model into RAM instead of memory-mapping it. This prevents page faults during inference and dramatically reduces cold start-b 1024 -ub 512: Reduced batch size from the default
The results were immediate and significant. Speed went from 23.4 to 26.4 tok/s, a 12 per cent improvement. And cold start dropped from 8 minutes to 1.5 minutes.
The --no-mmap change alone was worth it for the cold start improvement. If the service crashes and systemd restarts it, it is back online in 90 seconds instead of 8 minutes.
Why thread tuning matters on DGX Spark: The Grace CPU has 20 Neoverse V2 cores, but the default thread count may not be optimal for this specific workload. Explicitly setting 16 threads gave the GPU enough breathing room while keeping CPU-side operations like tokenisation and routing fast.
Phase 9: Jinja Chat Template
We downloaded a MiniMax-specific Jinja chat template for cleaner tool calling. It produced a warning but did not affect functionality. We included it in the production config for future-proofing.
Phase 10: ik_llama.cpp (Alternative Engine)
ik_llama.cpp is a fork with optimised CPU kernels (IQK) for quantised models. We wanted to see if its kernels could squeeze out more speed.
Building it on the DGX Spark required a fix. The Grace CPU (Neoverse V2) supports FP16 arithmetic and DOTPROD instructions, but GCC's -march=native flag does not enable the compiler macros for these features. This is a bug in GCC's auto-detection for this specific CPU.
The fix: replace -march=native with -march=armv8.2-a+dotprod+fp16.
After building, the benchmark showed identical performance to mainline: 26.4 tok/s. The IQK kernels optimise CPU inference, but when all model layers run on GPU (which they do with -ngl 999), CPU optimisation does not help.
This build fix is a genuine community contribution. Anyone building C++ projects with ARM NEON FP16 intrinsics on DGX Spark will hit this issue. The fix is simple but non-obvious.
Phase 11: llama.cpp-dgx Fork
The dgx fork includes MiniMax M2 architecture support and DFlash MTP. We built and benchmarked it at 24.7 tok/s, slightly slower than mainline. DFlash only works with Qwen targets, so no help for M2.7.
Phase 12: Pushing Context to 160K
We tested 163,840 tokens (160K) with q4_0 KV cache. It loaded successfully but only had 2.7GB of VRAM free. That is below the 5GB safety margin. A long prompt or multi-turn conversation could cause an out-of-memory crash at any time.
131K is the confirmed safe ceiling for this model on the DGX Spark.
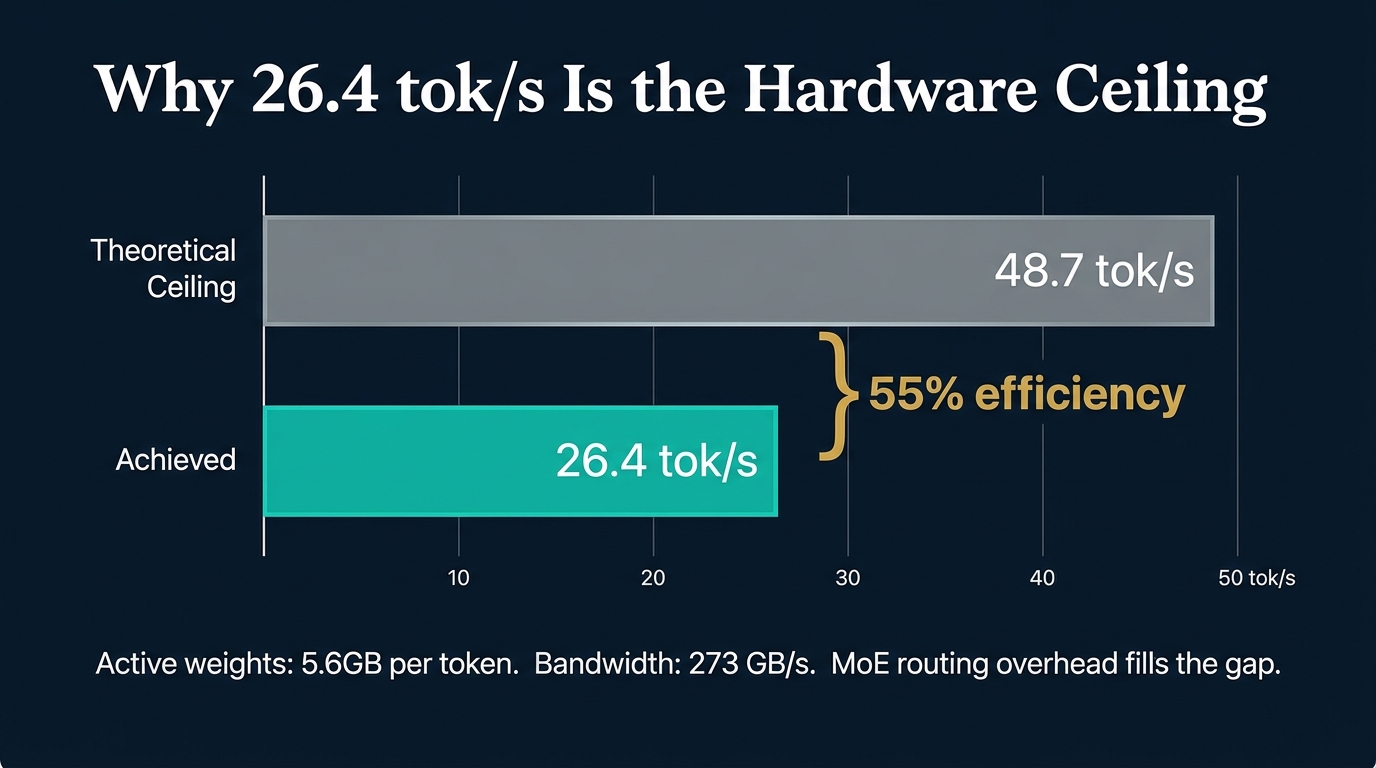
Why 26.4 tok/s Is the Hardware Ceiling
Understanding why we cannot go faster requires understanding the hardware bottleneck.
The DGX Spark has 273 GB/s of memory bandwidth shared between CPU and GPU. This is the speed limit. Every token requires loading the active model weights from memory to the GPU.
M2.7 activates about 10 billion parameters per token (8 of 256 experts). In IQ4_XS quantisation, that is roughly 5.6 GB of weight data per forward pass.
Theoretical ceiling: 273 GB/s divided by 5.6 GB = about 48.7 tok/s.
We achieved 26.4 tok/s, which is 55 per cent of the theoretical ceiling. The remaining 45 per cent is consumed by expert routing overhead, attention computation, kernel launch latency, and other GPU operations.
For comparison, Qwen 3.6 achieves much higher efficiency (120 tok/s with only 10GB weights) because its active parameter count is much smaller (3B vs 10B) and it runs through Atlas's hand-tuned CUDA kernels.
55 per cent efficiency is typical for mixture-of-experts models running through llama.cpp. MTP could theoretically push toward 80-90 per cent by hiding latency behind speculative tokens, but MTP is blocked for M2.7 due to its unique vocabulary.
What We Learned
Lesson 1: Thread tuning matters more than fancy kernels. The biggest speedup came from setting -t 16 -tb 16, not from rebuilding with special flags or switching engine forks. Simple, obvious, easy to overlook.
Lesson 2: --no-mmap is a hidden win. Loading the entire model into RAM instead of memory-mapping it has zero impact on inference speed but slashes cold start from 8 minutes to 90 seconds. For production services that need to restart quickly, this is essential.
Lesson 3: The Grace CPU has a GCC bug. -march=native does not enable FP16 or DOTPROD macros on Neoverse V2, despite the CPU supporting them. Anyone building C++ projects on DGX Spark should use -march=armv8.2-a+dotprod+fp16 instead.
Lesson 4: MTP depends on vocabulary compatibility, not just architecture. M2.7's 200,064-token vocabulary is unique to MiniMax. No draft model exists. This is the real blocker, not lack of software support.
Lesson 5: Verify everything with benchmarks. FA_ALL_QUANTS rebuild? No change. Batch tuning? No change. ik_llama.cpp? No change. Thread tuning? 12 per cent improvement. The only way to know is to measure.
Lesson 6: 55 per cent bandwidth efficiency is the MoE norm. When you only activate 8 of 256 experts, the routing overhead and attention computation consume nearly half your available bandwidth. This is not a software problem. It is a hardware physics problem.
The Final Production Configuration
For anyone wanting to replicate this setup on a DGX Spark, here is the exact production command we landed on after all 12 phases:
llama-server -m MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf -ngl 999 -c 131072 -ctk q4_0 -ctv q4_0 --flash-attn on -t 16 -tb 16 -b 1024 -ub 512 --no-mmap --cont-batching --host 0.0.0.0 --port 8000 --temp 0.6 --repeat-penalty 1.1 --frequency-penalty 0.3
What each flag does:
-ngl 999: Offload all layers to GPU-c 131072: 131K token context window-ctk q4_0 -ctv q4_0: 4-bit KV cache (halves memory usage)--flash-attn on: Optimised attention computation-t 16 -tb 16: 16 threads for inference and batching (the key speedup)-b 1024 -ub 512: Batch and micro-batch sizes--no-mmap: Load entire model into RAM (fast cold start)--cont-batching: Support concurrent requests efficiently
Our Two-Spark Cluster Now
The two-machine setup that powers all our private AI work:
Spark 1 (Reasoning): MiniMax M2.7 at 26.4 tok/s, 131K context. Handles complex reasoning, research, and planning tasks.
Spark 2 (Speed): Qwen 3.6 35B at 120 tok/s, 1M context. Handles tool calls, routing, and fast responses.
Together they cost roughly $15,800 AUD in hardware with zero ongoing API costs. All data stays on the desk.
Frequently Asked Questions
What is MiniMax M2.7?
MiniMax M2.7 is a mixture-of-experts language model with 229 billion total parameters but only 10 billion active per token. It uses 256 expert modules and activates 8 per token. This gives it the knowledge of a massive model while keeping computational costs manageable. It was created by MiniMax and released as an open-weight model.
What is IQ4_XS quantisation?
IQ4_XS (Importance Matrix Q4 Extra Small) is a quantisation method that compresses model weights to approximately 4.5 bits per parameter. It uses an importance matrix to preserve accuracy in the most critical weights while aggressively compressing less important ones. The result is a model that fits in less memory with minimal quality loss compared to the original.
What is the Grace CPU GCC bug?
On the NVIDIA DGX Spark's Grace CPU (Neoverse V2), GCC's -march=native flag does not enable compiler macros for FP16 arithmetic or DOTPROD instructions, even though the CPU supports them. The fix is to use -march=armv8.2-a+dotprod+fp16 instead. This affects any C++ project using ARM NEON FP16 intrinsics on this hardware.
Why can M2.7 not use multi-token prediction?
M2.7 has a unique 200,064-token vocabulary. Multi-token prediction requires a smaller draft model that shares the same vocabulary. No existing small model shares M2.7's vocabulary. Enabling MTP would require training a custom draft model from scratch, which is a research project.
What is memory bandwidth and why does it limit speed?
Memory bandwidth is how fast data can move from RAM to the GPU. On the DGX Spark it is 273 GB/s. Every token generated requires loading the active model weights from memory. With 5.6 GB of active weights per token, the theoretical maximum is about 48.7 tok/s. Real-world efficiency is typically 50-60 per cent due to routing and computation overhead.
Can I replicate this on a Mac?
Yes, MiniMax M2.7 GGUF runs on Mac Studio with sufficient unified memory (128GB+). Use llama.cpp with similar flags. Expect slightly lower performance due to different GPU architecture. The thread tuning and --no-mmap optimisations apply on Mac as well.

