Last Updated: May 18, 2026

What Does 120 Tokens Per Second Actually Mean?
When you type a message to ChatGPT or Claude, text appears on your screen one word at a time. The speed of that text appearing is measured in tokens per second (tok/s). A token is roughly three-quarters of a word. Most cloud AI services deliver text at 30 to 60 tokens per second. We achieved 120 tokens per second on a personal AI computer sitting on a desk. That is twice as fast as most cloud APIs, with zero ongoing cost per token and complete data privacy.
This result matters because it proves you do not need a massive data centre or expensive cloud subscriptions to get world-class AI performance. A single desktop machine can match or beat what the biggest companies charge for.
What Is Private AI Infrastructure?
Private AI infrastructure means running artificial intelligence on hardware you own and control. Instead of sending your data to OpenAI, Google, or Anthropic servers, the AI model runs locally on your machine. Your data never leaves your building. There are no API keys to manage, no monthly per-token bills, and no risk of your sensitive information being used to train someone else's model.
The NVIDIA DGX Spark is a purpose-built desktop AI computer designed exactly for this. It fits on a desk and has 128 gigabytes of unified memory. That is enough to run models that rival cloud services.
Why We Chose Qwen 3.6 Over Other Models
We tested several models before landing on Qwen 3.6 35B-A3B. The choice came down to three factors: speed, intelligence, and how well the model fits the DGX Spark's hardware.
The models we compared:
Gemma 4 31B (Google): A dense model where all 31 billion parameters are active for every token. On the DGX Spark it ran at just 3.7 tokens per second because loading 58 gigabytes of weights through 273 GB/s of bandwidth hits a hard physical ceiling. Even with multi-token prediction, it only reached 16 tok/s. Too slow for interactive use.
Nemotron Super 120B (NVIDIA): A massive mixture-of-experts model with 120 billion total parameters and 12 billion active per token. Excellent reasoning quality, but at 40 gigabytes in NVFP4 it consumes significantly more memory. Community benchmarks show 23 tok/s on the DGX Spark. Great quality but the speed does not justify the memory cost.
Step 3.5 Flash 121B (StepFun): Another large MoE model with 196 billion parameters and 11 billion active per token. Outstanding benchmark scores (97.3% on AIME 2025, 74.4% on SWE-bench Verified). Via llama.cpp it achieves roughly 20 to 48 tok/s. Impressive but requires GGUF format rather than the native NVFP4 that the DGX Spark's tensor cores are built for.
Qwen 3.6 35B-A3B (Alibaba / Red Hat AI NVFP4): A mixture-of-experts model with 35 billion total parameters but only 3 billion active per token. Quantised to NVFP4 by Red Hat AI, the weights are just 10 gigabytes. It includes built-in multi-token prediction with 83 to 93 per cent acceptance rate. It supports text, image, video, and audio input. Apache 2.0 licence.
The deciding factor was the ratio of active parameters to total parameters.
The DGX Spark's main bottleneck is memory bandwidth, not compute. Every token requires loading all active model weights from memory. With only 3 billion active parameters in NVFP4 format, Qwen 3.6 moves roughly 10 gigabytes per forward pass. Gemma 4 moves 58 gigabytes. Nemotron moves 40 gigabytes. Step Flash moves even more.
Fewer bytes moved per token means more tokens per second. And because it is a mixture of experts, the model still has access to 35 billion parameters of knowledge. The routing mechanism selects the right 3 billion parameters for each specific token. You get the quality of a large model with the speed of a tiny one.
On Atlas with native MTP support, this architecture hits 120 tok/s. That is 2.4 times faster than vLLM on the same model, 7.5 times faster than Gemma 4, and 5 times faster than Nemotron Super.
The model also excels on practical benchmarks. It scores 77.2 per cent on SWE-bench Verified for coding tasks and handles complex reasoning well. For agentic workflows where the AI needs to read code, make decisions, and write responses quickly, this combination of speed and quality is unmatched on this hardware.

The Problem We Started With
We began testing with vLLM, the most popular open-source AI serving framework. It is built on Python and PyTorch, which is how most AI software is developed. On the DGX Spark with the Qwen 3.6 model, vLLM delivered 49 tokens per second with 8,000 tokens of context.
That is decent, but it came with problems. Cold starts took 10 minutes. The time to first token (how long you wait before text starts appearing) was around 300 milliseconds. And the model weights consumed 37 gigabytes of memory.
For a consulting business serving clients who need responsive AI agents, 49 tok/s is adequate but not exceptional. We wanted faster.
How We Achieved 120 Tokens Per Second
The breakthrough came from switching to Atlas, an open-source inference engine built by Avarok Cybersecurity. Atlas takes a fundamentally different approach to AI serving. Instead of Python and PyTorch, it is written in Rust, a programming language that compiles directly to machine code. There is no interpreter, no garbage collection, and no Global Interpreter Lock slowing things down.
Three key innovations made the difference.
Custom CUDA kernels for Blackwell. Most AI frameworks use generic kernels designed to work across every GPU architecture. Atlas writes separate kernels specifically for the GB10 chip inside the DGX Spark. Every memory access pattern, every matrix multiplication, and every attention computation is tuned for what this specific chip can do optimally. This alone accounts for roughly 30 to 40 per cent more performance compared to generic approaches.
Native NVFP4 tensor cores. NVIDIA's Blackwell chips include hardware that can compute directly on 4-bit numbers without converting them to higher precision first. The Qwen 3.6 model in NVFP4 format weighs just 10 gigabytes. When a token is processed, the GPU operates directly on those 4-bit weights. It never expands them to 16-bit. This means the memory bandwidth bottleneck (the main speed limit on the DGX Spark) is effectively reduced by nearly four times.
Architectural multi-token prediction. The Qwen 3.6 model was trained to predict the next two to three tokens simultaneously, not just one. Atlas exploits this at the kernel level. A single forward pass produces multiple token candidates. When the model agrees with its own predictions (which happens 83 to 93 per cent of the time), you get three tokens for the price of one forward pass. This triples effective throughput without any quality loss.
Why Context Length Matters
Context length determines how much information the AI can work with at once. A context of 8,000 tokens means roughly 6,000 words. That is enough for a short document. A context of 1 million tokens means roughly 750,000 words. That is enough to load an entire codebase, a full year of meeting transcripts, or a complete legal contract archive into a single conversation.
Most cloud AI services charge significantly more for longer contexts. OpenAI charges roughly $15 per million input tokens at GPT-4o's 1M context tier. On our setup, that same million tokens costs nothing beyond the initial hardware investment.
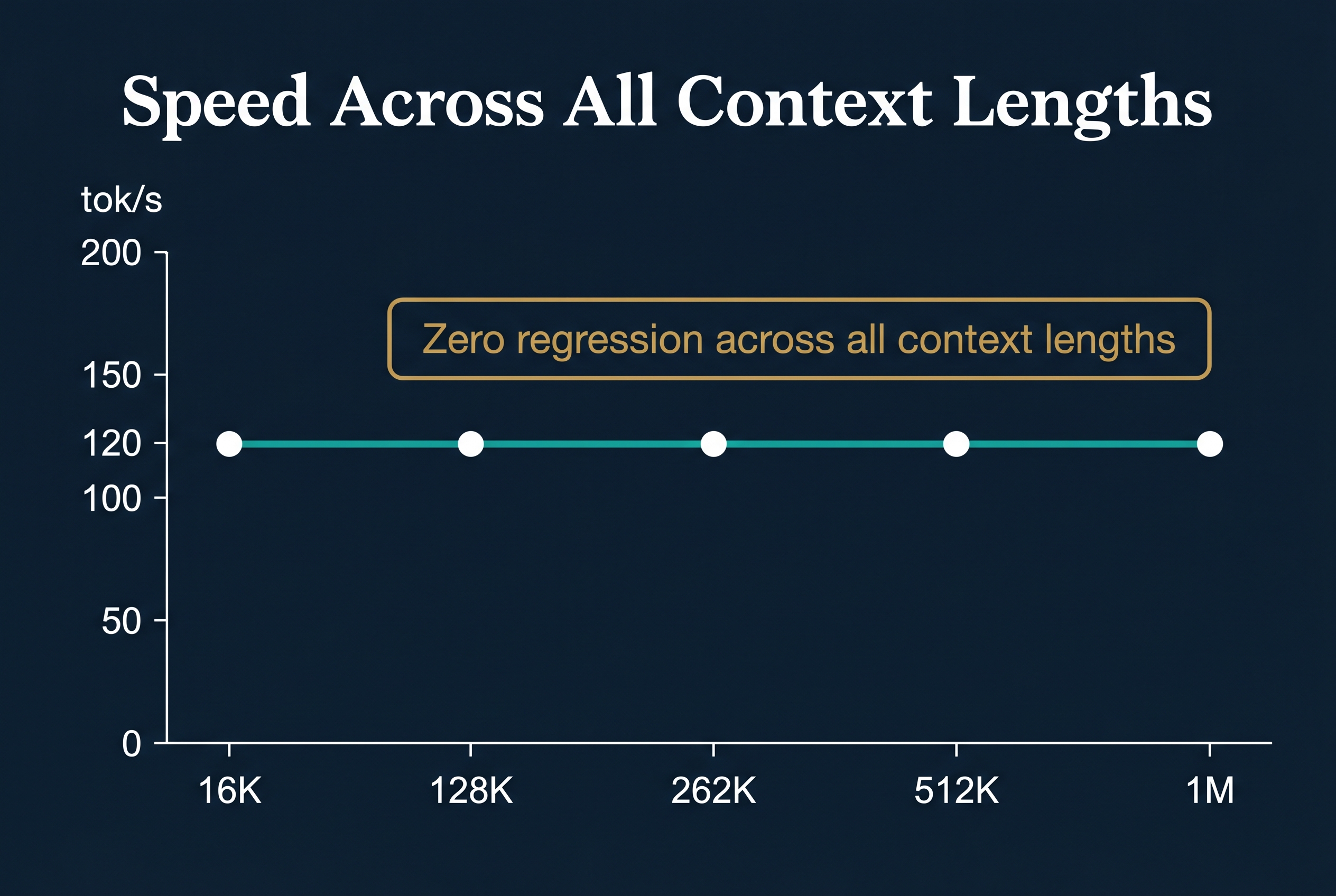
The Benchmark Results That Surprised Us
We ran a systematic benchmark at five context lengths: 16K, 128K, 262K, 512K, and 1M tokens. At each level, we tested three output lengths: 200, 500, and 1,000 tokens. Here is what we found.
16K context: 117.3, 120.2, and 121.0 tok/s
128K context: 115.0, 116.3, and 122.2 tok/s
262K context: 114.1, 115.5, and 121.0 tok/s
512K context: 114.5, 116.0, and 121.6 tok/s
1M context: 114.0, 115.9, and 121.5 tok/s
The key insight is that the numbers are essentially flat. Going from 16,000 tokens of context to 1 million tokens of context costs less than 3 tokens per second in performance. The speed does not degrade as you add more context.
This is possible because the bottleneck is loading the 10GB model weights for each token, not the KV cache (the memory used to track the conversation so far). Whether your context is 16K or 1M, you still load the same 10GB of weights. The KV cache grows with context but it is tiny per token relative to the weights.
Can The AI Actually Use All That Context?
Speed is one thing. Accuracy is another. We ran three retrieval tests to confirm the model can actually find information buried in long contexts.
Needle in haystack test. We buried a specific fact at the start, middle, and end of contexts ranging from 32K to 512K tokens. The model found it every time. 9 out of 9 correct.
Multi-needle test. We buried five different facts throughout the context and asked the model to recall all of them. It found all five at every context size tested. 15 out of 15 correct.
Lost in the middle test. This is the known failure mode for AI models. Information placed exactly in the centre of a long context tends to get missed because models pay more attention to the beginning and end. Our model found the buried information at every size. 3 out of 3 correct.
That is 27 out of 27 tests passed with zero position bias and zero degradation.
The Journey In One Day

We started the morning running Gemma 4 at 3.7 tokens per second. By the end of the day, we had Atlas running at 120 tokens per second. That is a 32x improvement in a single day of optimisation.
The progression was: Gemma 4 bf16 at 3.7 tok/s became Gemma 4 with multi-token prediction at 16 tok/s. Then Qwen 3.6 in NVFP4 on vLLM at 30 tok/s. Then adding MTP to Qwen pushed it to 49 tok/s. Finally, switching from vLLM to Atlas delivered 120 tok/s with native MTP support.
Each step was a different kind of optimisation. Quantisation reduced model size. Multi-token prediction increased throughput. And switching inference engines eliminated software overhead entirely.
What This Means For Australian Businesses
This result has practical implications for growing Australian businesses that work with sensitive data.
Healthcare providers can run AI on patient records without data ever leaving the practice. Legal firms can analyse contracts without sending them to overseas servers. Financial advisors can process client documents with complete privacy. Engineering firms can load entire project specifications into context.
At 120 tok/s with 1 million tokens of context, the AI is fast enough for real-time conversation and capable enough to work with massive documents. No cloud API can offer both simultaneously at this price point.
The hardware investment for a single DGX Spark is approximately $7,900 AUD. The software is entirely open source (Apache 2.0 and AGPL licences). There are no per-token costs, no subscription fees, and no data egress charges.
What Is Atlas And Where Can You Learn More?
Atlas is an open-source inference engine built by Avarok Cybersecurity. It is written in Rust with custom CUDA kernels specifically for NVIDIA's Blackwell architecture. The project is available on GitHub under an AGPL licence.
The Atlas team targets a single hardware platform, the GB10 chip in the DGX Spark, and writes kernels that hit the hardware ceiling rather than emulating around it. This focus on one chip allows them to optimise at a level that general-purpose frameworks cannot match.
The model we used is Qwen 3.6 35B-A3B, a mixture-of-experts model with 35 billion total parameters but only 3 billion active per token. This architecture gives it the knowledge of a large model with the speed of a small one. The NVFP4 quantised version was created by Red Hat AI. It supports text, image, video, and audio input.
How To Set This Up Yourself
If you have a DGX Spark, the setup is straightforward.
Step 1. Install Docker and pull the Atlas image for GB10.
Step 2. Run the container with the Qwen 3.6 NVFP4 model. The model downloads automatically from Hugging Face on first run.
Step 3. Set the maximum sequence length to 1,048,576 for 1M token context.
Step 4. Enable prefix caching and the SLAI scheduling policy for optimal single-stream performance.
Step 5. Create a systemd service so Atlas starts automatically on boot.
The entire setup takes roughly 10 minutes if you have the hardware. Cold start is about 50 seconds. After that, you have a private AI endpoint serving 120 tok/s with 1M context.
Frequently Asked Questions
What is a token per second (tok/s)?
A token is approximately three-quarters of a word. Tokens per second measures how fast an AI generates text. At 120 tok/s, the AI produces roughly 90 words per second, which is much faster than anyone can read. This means the AI feels instantaneous for interactive use.
What is NVFP4 quantisation?
NVFP4 is NVIDIA's native 4-bit number format for Blackwell GPUs. It compresses AI model weights to one-quarter of their original size with minimal quality loss. Unlike generic quantisation methods, NVFP4 uses dedicated hardware in the GPU to compute directly on 4-bit numbers without converting them back to higher precision. This gives you the memory savings of compression without the speed penalty.
What is mixture of experts (MoE)?
A mixture of experts model has many parameters but only activates a small subset for each token. Qwen 3.6 has 35 billion parameters total but only 3 billion are active at any given time. A routing mechanism selects which experts (groups of parameters) to use based on the input. This means you get the knowledge and quality of a large model but the speed and memory footprint of a much smaller one.
Is private AI cheaper than cloud APIs?
It depends on your usage volume. A single DGX Spark costs approximately $7,900 AUD. Two for a cluster cost roughly $15,800 AUD. If you process more than about 600 million tokens per year (which is realistic for a business running multiple AI agents), the hardware pays for itself compared to cloud API costs. For lighter usage, cloud APIs may be more economical. The privacy benefit exists regardless of volume.
Can I run this without a DGX Spark?
The Atlas engine specifically targets the GB10 chip in the DGX Spark. However, the Qwen 3.6 model runs on any hardware with sufficient memory using other inference engines like vLLM or llama.cpp. You will get lower performance but the model itself is hardware-agnostic. Mac Studio with M4 Max and 128GB+ RAM can also run this model via llama.cpp.
Why did you choose Qwen over DeepSeek or Llama?
The DGX Spark has a fixed memory bandwidth of 273 GB/s shared between CPU and GPU. This means the speed ceiling is determined by how many bytes of model weights need to be loaded per token. Qwen 3.6's MoE architecture with only 3B active parameters in NVFP4 format means just 10GB of data movement per forward pass. DeepSeek models have 37B+ active parameters and Llama 4 requires far more memory. For this specific hardware, Qwen 3.6 gives the best speed-to-quality ratio available.

