
Kimi K2.7 Code vs MiniMax M3: Open-Source AI Coding Models Compared
MiniMax M3 vs Kimi K2.7 Code compared head-to-head. Full benchmark table, cost analysis, and local deployment guide from dual DGX Spark testing.
12 July 20269 min read
Read more
Practical AI news, automation tips, and real-world insights to help your business stay ahead.
MiniMax M3 vs Kimi K2.7 Code compared head-to-head. Full benchmark table, cost analysis, and local deployment guide from dual DGX Spark testing.
Hermes Agent vs OpenAI Codex vs Claude Code compared. Which coding agent fits your workflow? Based on real dual DGX Spark deployment experience.

Colibri runs GLM-5.2 on a 25GB laptop via pure-C disk streaming. Architecture, benchmarks, DGX Spark support.
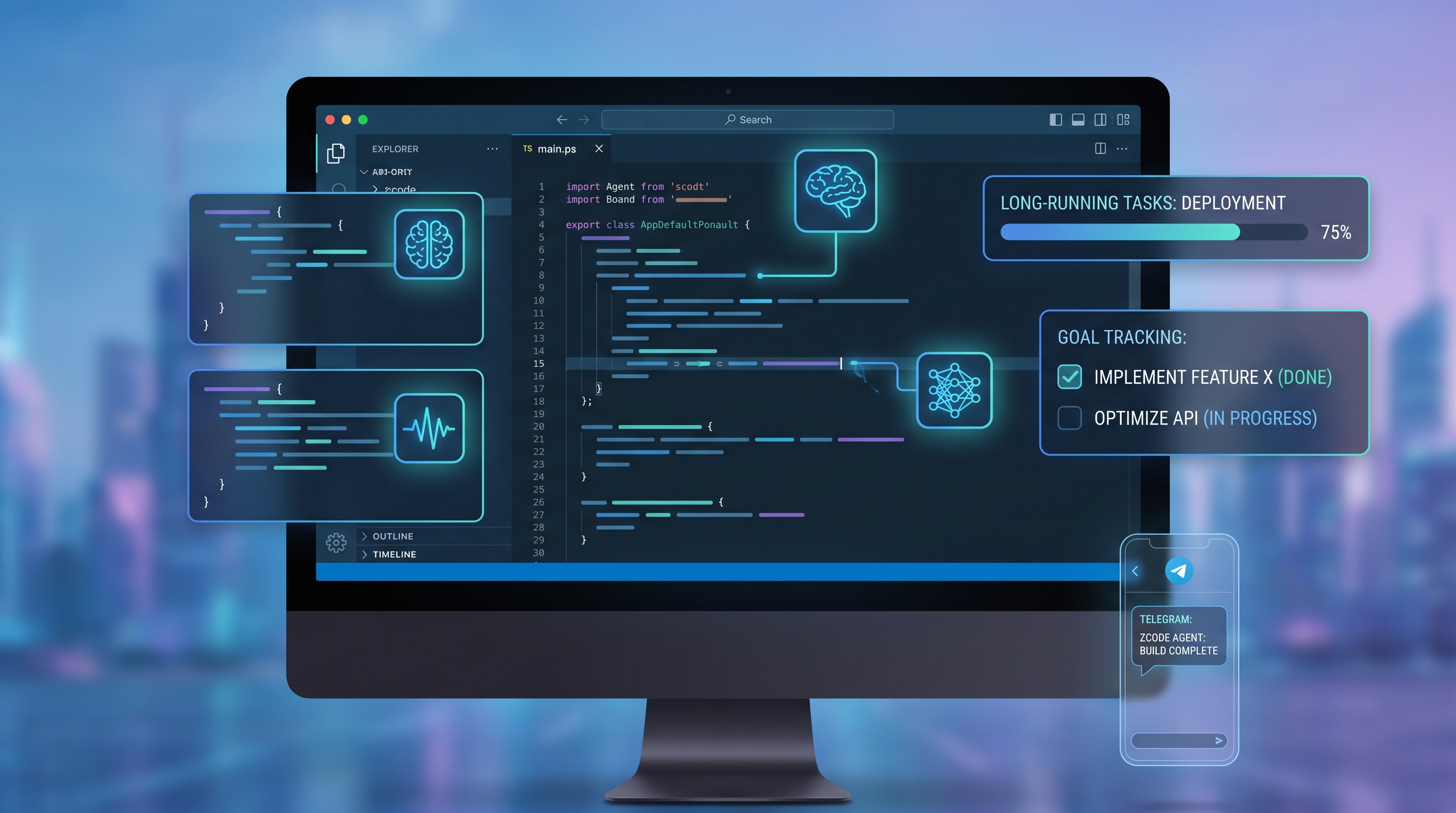
ZCode is Z.ai's open-source coding agent harness for GLM-5.2. How it compares to Cursor and Claude Code for agentic coding workflows.

Google OKF is a plain markdown format for AI agent knowledge exchange. Implementation guide, competitive analysis, and practical business applications.

GLM-5.2 is the strongest open-weight coding model with 81.0 on Terminal-Bench 2.1. Full review with benchmarks, architecture, and deployment options.

Kimi K2.7 achieves GPT-5.5-class performance at a fraction of the cost. Full review with benchmarks, local inference setup, and competitive analysis.

Tencent's HY3 delivers frontier-adjacent performance at $0.14 per million input tokens with a 5.4% hallucination rate. We compare it against GLM-5.2, DeepSeek V4, Kimi K2.6, and proprietary models on benchmarks, cost, and reliability.

Grok 4.5 delivers near-frontier performance at 80-90% lower cost than Fable 5. We break down the benchmarks, pricing, hallucination risks, and what it means for businesses building with AI in 2026.